Alibaba.com 性能优化经验总结
Create at 2023 01 11 • 51 min read • 技术 • performancealibaba
前言
本文原发于公司内部 ATA 平台,后来经过数据披露审核后,重新整理成为了这篇文章。所以文章内会有很多内部系统的介绍和链接,这些链接以及平台无法在非公司内网打开,但不影响文章整体的阅读和理解。本文同步发布于阿里开发者平台,地址:经验总结|我们如何进行Alibaba.com买家性能优化?
背景
为什么要做性能优化
对绝大多数网站来说,从宏观视角上看主要有两个因素影响最终的网站业务效益:
- 用户的整体规模
- 用户在网站内的转化率
业务效益 = 用户规模 * 转化率
所以为了提升业务效益,需要提升用户规模以及转化率。
用户规模
用户主要由新用户和老用户组成,新老用户也有各自的流量组成,但无论新老用户进入网站,都要经过从用户的客户端也就是站外落地到我们网站也就是站内这个过程。
尤其我们 Alibaba.com 是一个全球化的网站,从网络设施发达的欧美到欠发达的第三世界国家,都有用户通过电脑或者手机等设备访问我们的网站。
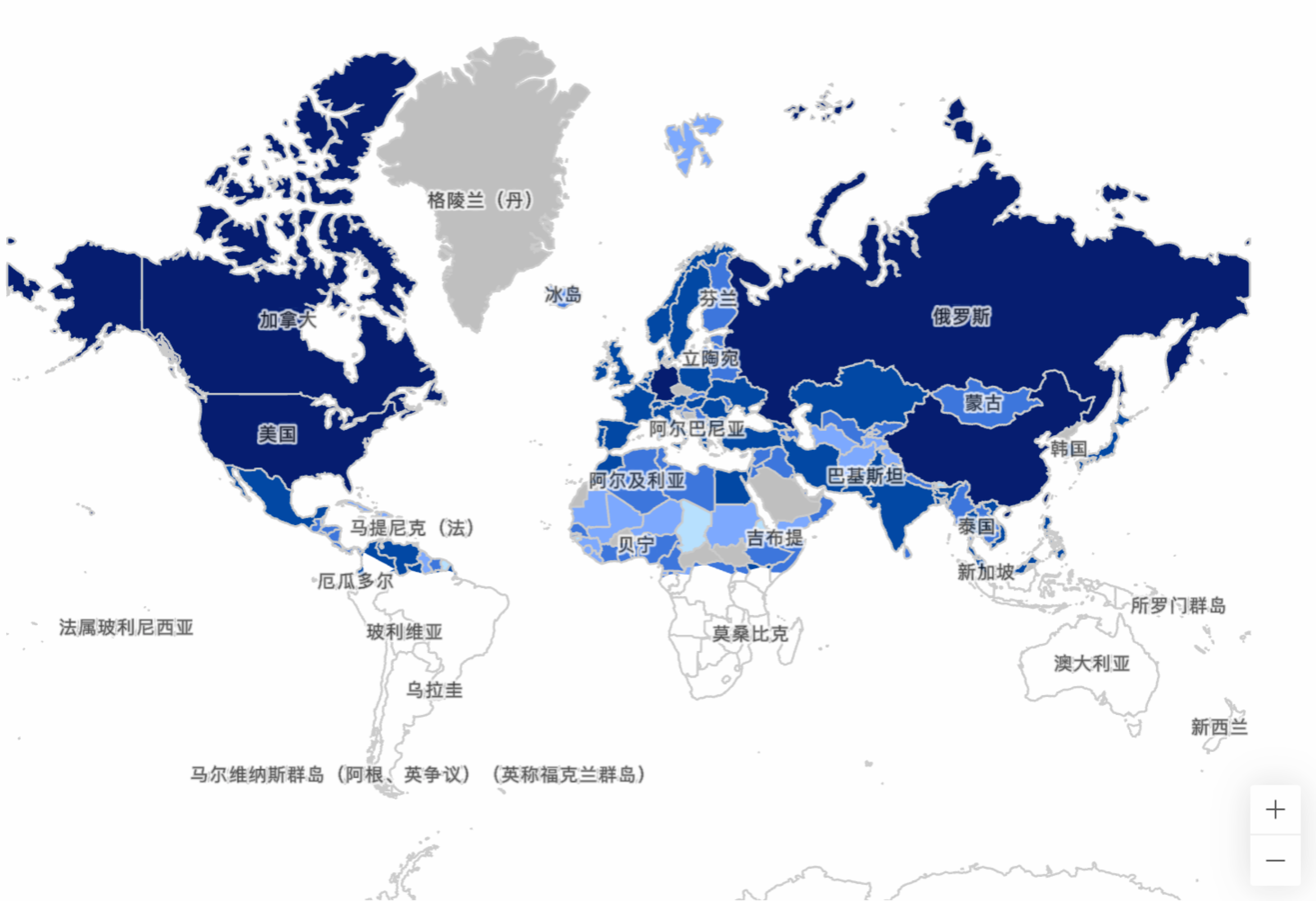 Alibaba.com 某页面的用户国家分布图
Alibaba.com 某页面的用户国家分布图
而复杂网络状况以及技术现状,会导致网页加载的缓慢,用户很可能无法忍受漫长的白屏等待而选择关闭网站,造成用户流失。 很多案例也说明了加载性能对用户规模的影响:
- At the BBC we’ve noticed that, for every additional second a page takes to load, 10 per cent of users leave.
- The result of rebuilding our pages for performance led to a 40 percent decrease in Pinner wait time, a 15 percent increase in SEO traffic and a 15 percent increase in conversion rate to signup.
所以网站的加载性能会直接影响到最终落地站内的用户规模。
转化率 影响转化率的因素非常多:网站提供的价值、用户的意愿度以及页面的用户体验都是重要的影响因素。而网站的交互性能,则是用户体验的一大影响因素。
如果一个网站打开过程中,页面元素各种抖动、滚动页面时卡顿掉帧,或者鼠标点击一个按钮时需要一秒钟才能响应用户的交互,都会极大地损害用户体验,直接影响用户的点击率和蹦失率,最终对转化率造成影响。
所以我们要做性能优化。
为什么总是做性能优化
每隔一段时间就要重新提性能优化,为什么:
- 性能腐化:随着业务的发展和功能迭代,越来越多的功能会逐步添加到现有的业务中,功能复杂度的增加也会导致性能现状逐步恶化
- 指标的迭代:随着技术的发展以及对用户极致体验的追求,会有更加准确和贴合用户体感的性能评价指标被提出和使用,老的性能评价指标指导下的优化结果在新的指标下并不一定适用
由于这些原因,我们现有的页面性能并不是很理想。
目标
我们将性能优化的目标定为买家前台核心浏览链路页面满足 Core Web Vitials 衡量指标下的 Good Url 标准。
什么是 Core Web Vitials
Core Web Vitials(后面简称为 cwv) 是 Google 为了衡量页面性能而提出的有多个指标组成的一套页面体验衡量标准,目前主要包含三个指标:LCP, FID, CLS。
- LCP: 最大内容绘制,测量加载性能。
- FID: 首次输入延迟,测量交互性能。
- CLS: 累计布局偏移,测量视觉稳定性。
为什么采用 Core Web Vitials 衡量指标
从上面对 cwv 的解释可以看到,核心指标从页面加载速度、用户输入性能以及页面的视觉稳定性三个方向衡量了一个好的页面性能应该具备的特点,这三个指标也是用户体验的核心要素。 相较于我们以前的衡量方式 hero element time ,即由每个业务线的开发自己定义一个关键页面元素,以它的渲染完成时间来衡量页面的性能,cwv 的指标明显要更加全面,而且更加通用,不易作弊且经受了整个行业的考验。
下面是 Google 官方对于真实网站在 cwv 指标优化下的性能提升情况的统计:
Why page performance matters Studies show that better Core Web Vitals improves user engagement and business metrics. For example:
- When a site meets the Core Web Vitals thresholds, research showed that users were 24% less likely to abandon page load.
- With each 100ms reduction in Largest Contentful Paint (LCP), web conversion rate for Farfetch increased by 1.3%.
- Reducing Cumulative Layout Shift (CLS) by 0.2 led Yahoo! JAPAN to a 15% increase in page views per session, 13% longer session durations, and a 1.72 percentage point decrease in bounce rate.
- Netzwelt improved Core Web Vitals and saw advertising revenues increase by 18% and page views by 27%.
- Reducing CLS from 1.65 to 0 significantly uplifted domain rankings globally for redBus.
可以看到无论是 LCP,FID 还是 CLS ,他们的提升都能实实在在的带来业务的提升,这也是我们要做性能优化的原因以及选择 cwv 作为衡量指标的原因。
更多选择 cwv 作为衡量指标的原因,可以参考:
所以我们将性能的衡量指标定为 Core Web Vitials,并将目标定为满足 Good Url 标准,即:
- LCP < 2500ms
- FID < 100ms
- CLS < 0.1
优化方法
性能优化是一个老生常谈的课题,网上有很多现成的方案和方法。当我们直接照搬这些方案或方法时,可能并不一定能快速达到我们的目标。 比如著名的雅虎军规里面说:静态资源尽量分散在多个域名下,以提高浏览器并发请求的数量。但随着技术的发展 HTTP2 的普及,这条方案已经并不适用了。又比如有文章说 js 里面的数组遍历方法 for 比 forEach 要快很多,所以为了更好的性能我们要用 for 来代替 forEach,你花了几天时间把所有 for 改成了 forEach 结果 cwv 指标根本没有任何变化。
所以我们要做性能优化,不能单纯的照搬别人的方案,而是要掌握性能优化的方法,正所谓理论指导实践。对于性能优化来说,方法就是:度量、分析和验证。
度量
如果我们不能衡量页面现状,那么优化也就无从谈起。
所以性能优化的首要事情就是要有度量页面的性能现状的方案,为后面的分析和优化提供数据支持。
前面提到我们选择 cwv 作为我们的性能衡量指标,Google 提供了很多 cwv 的检测方式,包括 PageSpeed Insights、Chrome 开发者工具、搜索控制台、web.dev 测量工具等测试工具和平台。
但它们都有一个问题,不能够实时检测线上实际用户的总体统计值,要么是只能本地单次通过类似 PSI(PageSpeed Insights)的测试来看单次评估结果,要么是类似 Google Search Console 这样只能在滞后一段时间以后才能看到大量用户的实际统计值。
而实时的性能数据对我们非常重要,如果没有实时数据,那么会有一下问题:
- 无法快速验证实验方案,每上一个方案等两周再看效果,这效率难以接受
- 对于一些大的改造,如果造成了性能的严重下跌,却没有实时数据的反馈,两周后再看数据时可能已经对业务造成了很大的损失
所以我们必须有一套实时观测性能数据的方案,来指导我们优化的策略或者优化方向是否正确。
最终我们选择 web-vitals来获取 cwv 的值,并在 ICBU 统一性能监控脚本 big-brother 中添加了相应的打点来上报每个用户的性能数据并建立了相应的性能监控和报表来实时观测页面的性能数据,详细可以参考:Google Core Web-Vitals 统计&监控。
_PS:现在可以直接接入 _agado来快速获取更加详细的性能数据。
分析
结合上一步获取的性能数据,我们可以系统性的分析当前每一个页面的性能现状。知道它现在到底慢不慢,为什么慢,具体哪里慢,这样的话我们也可以针对性的进行优化。
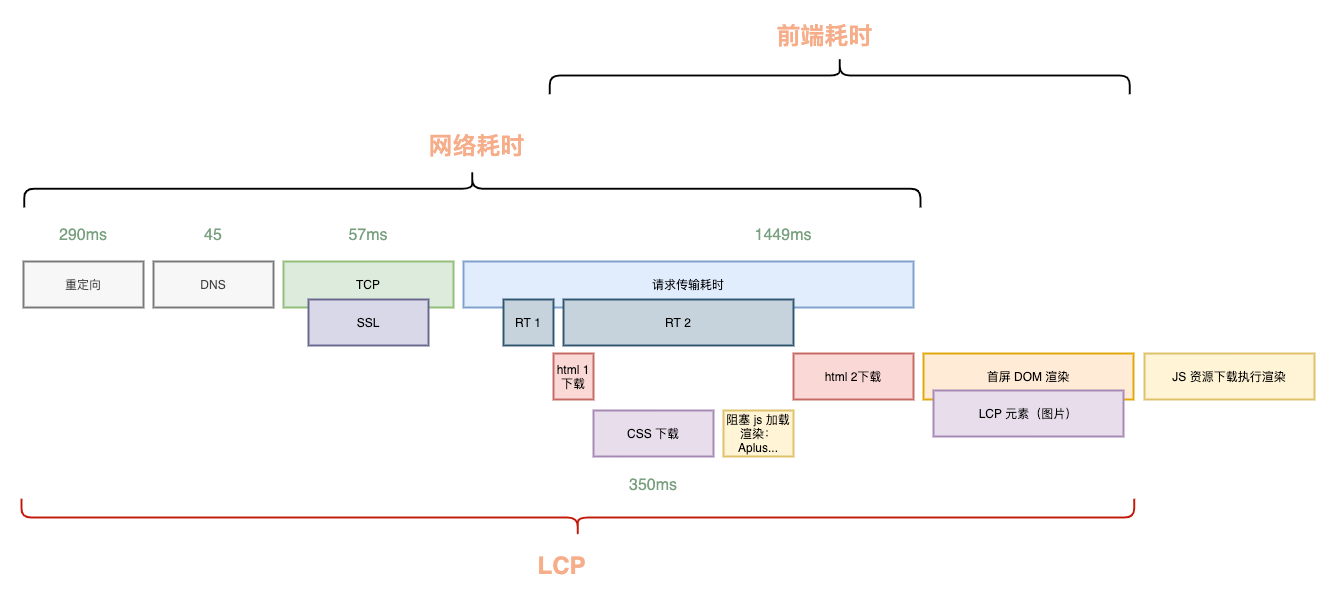
拿一个典型的前后端分离的页面来看,LCP 的组成部分如下:
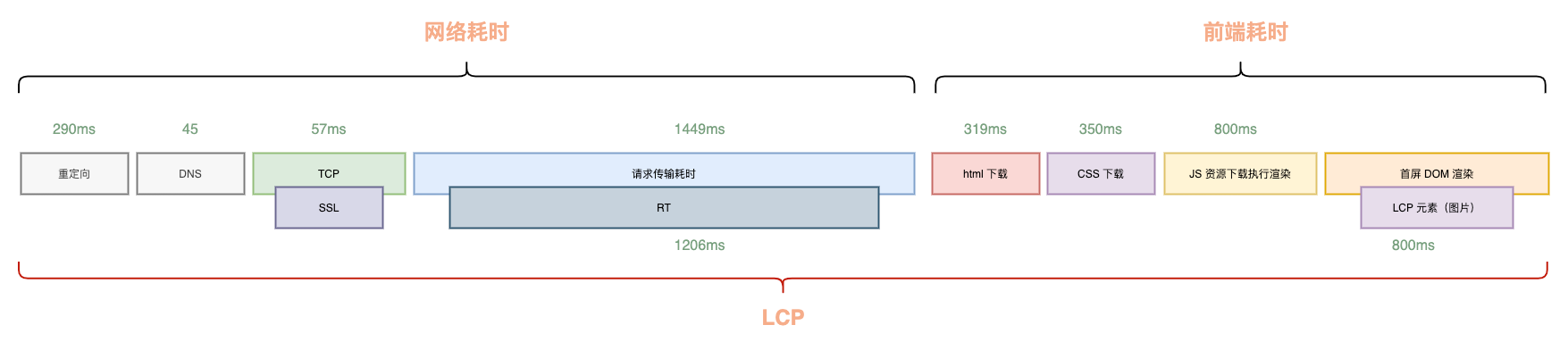
可以看到,从用户打开浏览器到页面的 LCP 出现需要经过:建联、后端响应,HTML 传输下载,前端资源下载再到最后的解析渲染,链路非常长,导致最终的 LCP 往往离 2500ms 相去甚远。
如何减少 LCP 的时间,不考虑技术细节的情况下我们不难想到,就是缩短每个耗时组成或者尽可能让他们并行,这也就是我们优化 LCP 的核心宗旨:能减少的减少,不能减少的并行。
从 LCP 的组成上来看,其中重定向、DNS 解析以及建联和网络传输的时间主要受三方或者用户自身的网络状况限制,我们能做的并不多。
所以核心的优化方向应该聚焦在我们能控制的网络耗时以外的地方,即:
- LCP 的时间线组成排布优化:即在现有的 LCP 时间线中,哪些可以去掉,哪些可以并行;
- LCP 的时间线组成中每一个步骤本身的耗时优化:即除了网络耗时以外,后端 RT 以及前端资源下载解析执行时间的优化;
对这两个方向的优化我们分别通过:渲染架构优化和关键渲染路径优化来进行分析优化,对于后端 RT 的优化本文暂不涉及。
渲染架构上的优化
从宏观视角上来看,渲染架构的选择是非常重要的,合理的架构选择可以提高系统的性能下限,为后续进一步优化打下基础。
按照 LCP 优化的核心宗旨:能减少的减少,不能减少的并行。从前面 LCP 构成图上不难看出:
- 传统的页面渲染是不依赖 js 加载的,也就是说这部分时间是有可能省掉的
- 前端资源的加载和后端响应两个大的耗时组成之间是串行的关系,有没有可能让它们并行
这两个优化方向对应了我们渲染架构上的优化方案:同构改造以及流式渲染。
同构改造
渲染架构下性价比最高的优化就是同构改造,在有基建支持的情况下可以以较少的人力投入获取有确定性的比较大的性能提升,一般来说,同构改造可以带来 500~800ms 的性能提升。
前面提到,我们现在绝大部分业务都是前后端分离的架构。这种架构的优势是降低了前后端沟通以及发布维护的成本,两端可以并行开发独立维护自己的代码库,稳定性也更高。但这种架构的问题是,由于前后端分离了,后端输出的 HTML 中只有骨架而没有内容,到了前端需要再进行一次渲染,这次前端渲染又依赖 js 的下载以及首屏数据的获取,导致渲染链路变长。
能不能把这次额外的渲染的时间省掉呢?答案是可以的,同构直出就是为了解决这个问题。同样是前后端分离的架构,可以在不损失开发效率以及合作效率的情况下,通过一套 js 代码同时跑在前端和后端来实现页面的直出。
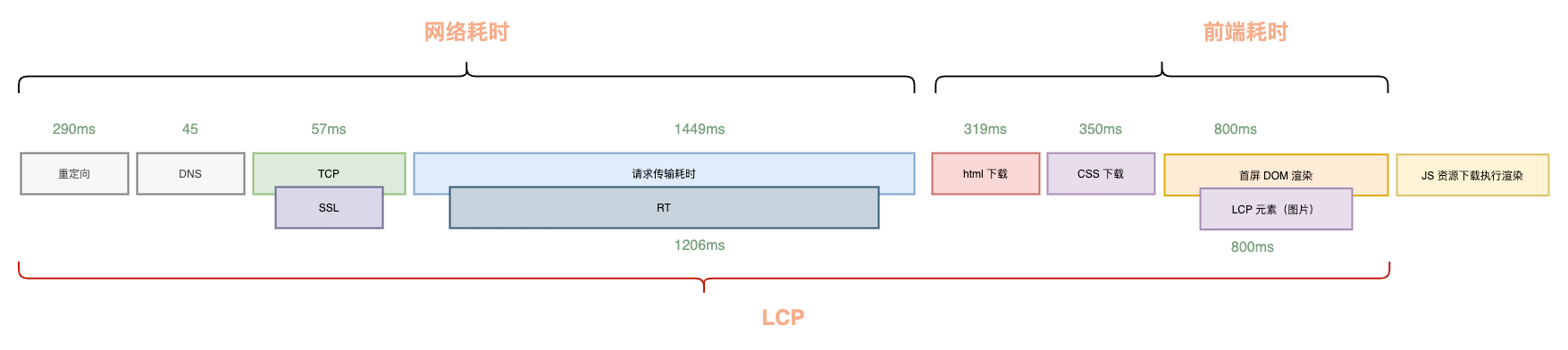
这样就可以省去前端额外的 js 下载以及解析执行渲染的时间,节省下来的时间一般是 500~800ms ,但它的代价就是需要额外维护一个同构服务。
同构服务的话,现在主要有通用同构服务 silkworm-engine(内部自建服务),店铺自建的同构服务,以及营销导购的接入集团天马平台所提供的同构服务。对于一般业务来说,对接 silkworm-engine 就可以了,对接本身成本也不高。
流式渲染
早在 2010 年,Facebook 的工程师就提出了 bigpipe 的页面渲染方案。通过将一个大的页面划分为多个 pagelet 来将渐进式的完成页面的渲染,核心是为了解决一次性渲染一个大的页面后端耗时过长的问题。
这个方案思路非常超前,但有一个缺点就是侵入性较大,以我们现有的技术架构下来说不太可能做这样的改造。 但它背后的原理即:http1.1 (在当时,现在 http2 以后默认支持)的分块传输编码的特性,可以指导我们来进行成本更低的优化,也就是流式渲染,将后端一次性的业务处理 vm 模板渲染并返回分为两步:
- 先返回是不依赖任何业务逻辑的 HTML 部分,浏览器拿到后可以先开始进行静态资源的下载
- 在返回第一段后,同步的去做业务逻辑处理,比如商品数据请求计算等,然后渲染 vm 并返回 HTML 剩余的 部分
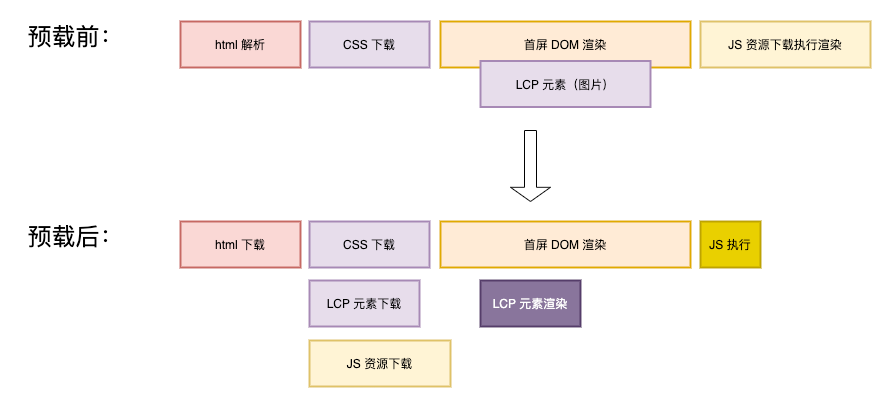
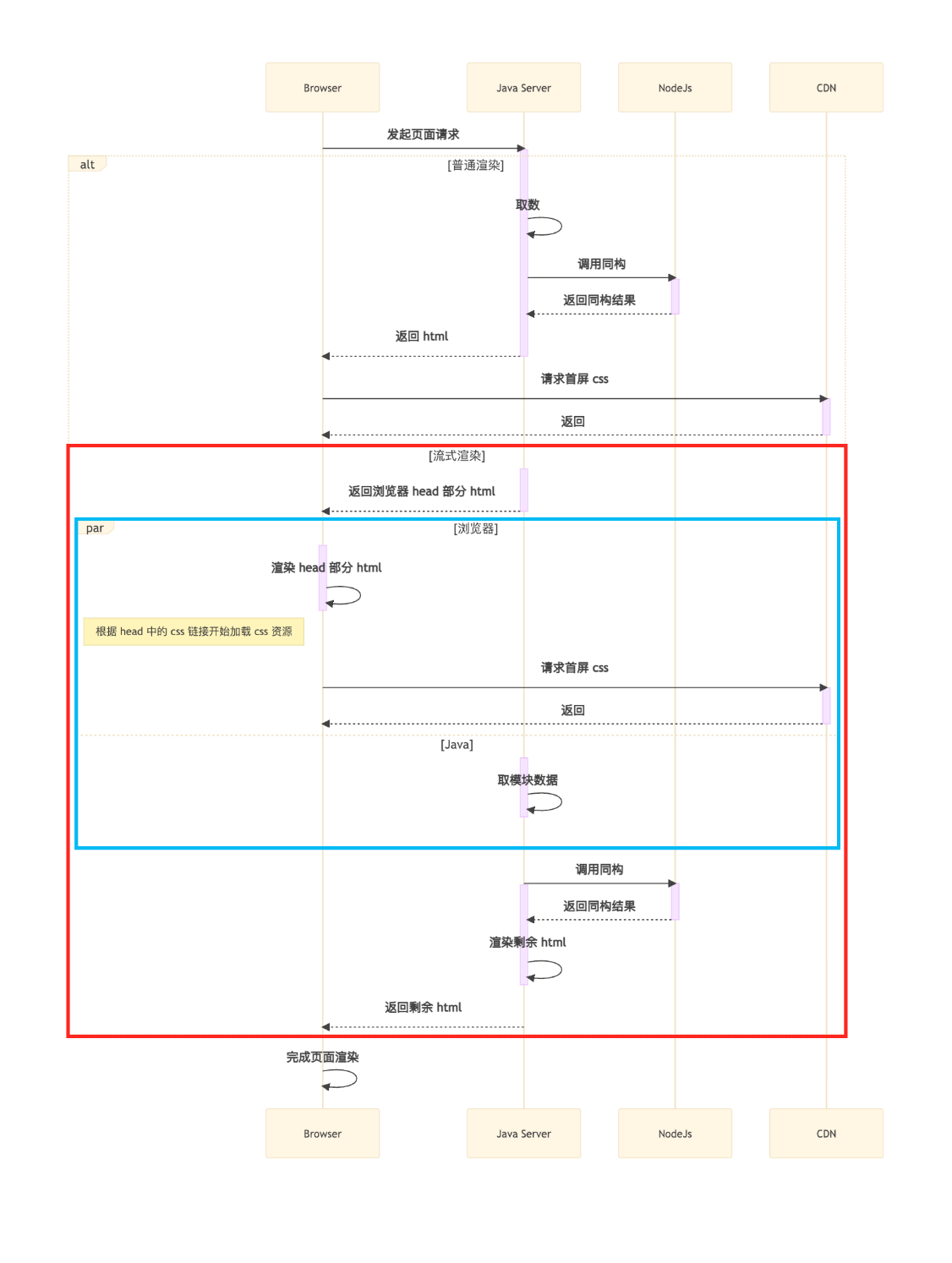 可以看到在流式渲染的方案下,蓝框中 的下载解析以及首屏 css 等资源的下载和后端的取数计算并行了。
可以看到在流式渲染的方案下,蓝框中 的下载解析以及首屏 css 等资源的下载和后端的取数计算并行了。
那么我们就可以节省 Min(前端首屏资源下载时间,后端 RT) 的时间,一般情况下可以有 300~500ms 左右的优化,优化后的时间线如下:
 流式渲染的对接也有了工程化的方案:
流式渲染的对接也有了工程化的方案:
- Java 应用参考 流式渲染- Java 端接入文档来进行对接
- NodeJs 下的 Egg 应用可以参考:Spark:五分钟接入流式渲染
渲染架构总结
通过同构改造和流式渲染两个渲染架构的上优化,一般情况下都能有 1s 以上的提升。而且不挑业务场景,只要按部就班的做,几乎所有页面都可以进行这两项改造并获得肉眼可见的增益。
同时除非做了其他渲染架构上的优化,一般情况下这 1s 以上的提升不会随着页面所在项目的功能迭代而腐化,确保了性能下限。
关键渲染路径优化
引用 MDN 上对关键渲染路径(Critical rendering path, 后文简称 CRP)的定义:
The Critical Rendering Path is the sequence of steps the browser goes through to convert the HTML, CSS, and JavaScript into pixels on the screen. Optimizing the critical render path improves render performance. The critical rendering path includes the Document Object Model (DOM), CSS Object Model (CSSOM), render tree and layout.
简单来说就是浏览器将 HTML,CSS 和 JavaScript 转换为屏幕上的像素所经历的步骤序列,优化包含文档对象模型(DOM),CSS 对象模型 (CSSOM),渲染树和布局在内的这些步骤可以提高首屏渲染性能。
CRP 的优化涉及到浏览器的渲染原理:
- 浏览器首先需要下载并解析 DOM 生成 DOM 树
- 在解析的 DOM 的过程中遇到 CSS 文件进行下载并解析,生成 CSSOM
- 根据 DOM 树和 CSSOM 生成渲染树
- 根据渲染树进行布局
- 布局完成后,将具体的内容绘制到屏幕上
当 DOM 或者 CSSOM 发生变化时,比如通过 js 操作了 DOM 节点或者动态插入了 style 标签等,浏览器会重新执行上述步骤。理解了 CRP 的原理,可以看到影响 CRP 的几个因素:
- HTML 文件的下载和解析时间
- CSS 文件下载和解析时间
- 同步 js 文件的下载和解析
- DOM 和 CSSOM 的大小
- 以及布局和绘制的时间
其中 HTML、CSS 以及同步 js 资源,我们称其为关键资源,因为它们的下载和解析时间会影响到 CRP 的各个阶段,这样我们只要优化关键资源的下载解析以及 DOM 和 CSSOM 的大小就好了。
- 对于关键资源的优化,可以通过缩减关键资源的数量,减少资源的大小以及调整关键资源的加载顺序和缓存等来优化;
- 对于 DOM 和 CSSOM 的优化,我们可以通过减少 DOM 节点的数量,减少 CSSOM 的大小,以及减少 DOM 和 CSSOM 的层级来优化;
缓存
可以通过静态资源缓存的方式来减少资源的下载时间,缩短关键路径长度,提高页面的渲染速度。 具体的方案:
- 设置资源缓存时间
- 静态资源走 CDN
- 动静分离
静态资源缓存配置
HTTP 缓存的具体规范定义本文不过多赘述,简单讲可以将缓存分为两类:
- 强缓存:缓存有效期内不发起请求直接使用本地缓存的内容
- 弱缓存 or 协商缓存:本地缓存过期后发起请求和服务器协商后再使用本地的缓存
对于一般的 Assets 应用来说,可以通过在项目根目录下添加 .assetsmetafile 文件,来自己指定资源的缓存时间,下面的示例是让浏览器以及 CDN (特定厂商)都缓存 1 年的配置:
cache-control:max-age=31536000,s-maxage=31536000
这样,只要资源所在的应用没有发布(仅针对非覆盖式发布资源,链接没有发生变化),那么一年的请求都直接走缓存的内容。
上 CDN
众所周知 CDN 可以通过自己强大的网络和服务器,将静态资源缓存到离用户最近的节点上,从而减少资源的下载时间。
CDN 静态加速
虽然静态资源上 CDN 是一个常规操作,但本文依然要把静态资源上 CDN 提出来是因为我们网站仍然有一些类似 的资源并没有走 CDN 分发,而是需要用户每次从源站请求下载资源。
CDN 动态加速
CDN 动态加速这个概念可能不是很常见,它的“动态”是相较于静态加速中“静态”来说的,也就是作用的对象的不同。
原理上简单来说,就是利用 CDN 天然的优势:有距离用户近的边缘节点,并且分布广泛。通过 CDN 厂商专门的优化,从 CDN 的节点机器中来寻找一条从用户到源站的更优线路,避免走外网的层层网关。从而缩短 CDN 节点于源站之间的网络耗时,用户的动态请求走 CDN 节点来回源到服务器,会比用户自己访问源服务器要快很多。
根据我们的统计,动态加速的收益在 200ms+ 。
提高缓存命中率
如果发布频率过高,由于版本号的变化导致资源对应的 url 频繁发生变化,那么本地的缓存除了占用本地的存储资源外已经失去了它原本的作用。
所以我们需要提高页面静态资源的缓存命中率,一般提高缓存命中率的方法就是动静分离。
可以通过对页面依赖的 js,css 进行分层,将公共的依赖比如 React、ReactDOM、Fusion 等打包成一个公共的 bundle 我们称其为静态资源,将业务相关的依赖打包成一个业务相关的 bundle 我们称其为动态资源。
由于静态资源的发布频率是远远低于动态资源的发布频率的,在绝大多数功能迭代的时候,只会发布上层业务应用。对于用户来说就只需要下载动态资源即可,而静态资源由于没有变动,所以可以直接从缓存中读取,加快资源加载速度。
这样就可以提高整体的资源缓存命中率,避免整个页面打一个 js 或者 css bundle 导致的哪怕是一行代码的发布,也需要用户重新下载整个 js, css bundle 包的问题。
建联
前面提到著名的雅虎军规里面说:静态资源尽量分散在多个域名下,以提高浏览器并发请求的数量。这是由于浏览器限制同一个域名下的请求数量,受限于当时 HTTP1.x 下一个 TCP 连接只能处理一个 http 请求的原因,为了能让浏览器能在同一时间对并行请求多个资源而提出的优化方案。
到了 HTTP2 时代,一个 TCP 连接就可以并行进行多个请求了,配合 HTTP1.1 的 Connection: Keep-Alive 来进行连接的复用,之前的优化方案已经没有太大的意义了。
域名收拢
甚至由于将资源分布在了不同的域名下,每个域名的都需要重新进行 DNS 解析、建联等过程,原本的优化手段已经变成了负向优化了。
为此需要将分布在多个不同域名下的地址收敛到一个域名下,减少 DNS 解析的次数并通过连接复用和并发请求获得更好的效果。
关于更多 HTTP2 的特性,可以参考:HTTP/2 – A protocol for greater performance
提前建连
前面提到 DNS 的解析以及建联都是非常耗时的操作,为此浏览器提供了提前进行 DNS 解析以及建联的方法,分别是:dns-prefetch 以及 preconnect。
dns-prefetch 是 HTML5 新增的一个属性,用于告诉浏览器提前解析某个域名,这样在浏览器需要解析这个域名的时候就不需要再去解析了,可以直接使用缓存中的结果。DNS-Prefetch 可以通过两种方式使用:
<link rel="dns-prefetch" href="https://s.alicdn.com/" />
preconnect:告诉浏览器提前建立 TCP 连接,DNS 解析以及 TLS 握手等操作,这样在浏览器需要使用这个域名的时候就不需要再去做这些操作了,可以直接使用缓存中的结果。在 head 标签添加如下的 meta 标签就可以了:
<link rel="preconnect" href="https://s.alicdn.com" />
PS: 需要注意,preconnet 真实建立了连接,属于比较重的操作,所以仅在关键资源对应的域名上使用,否则提前建立过多的连接可能会对页面造成负向作用。 由于 dns-prefetch 有着比 preconnet 更好的浏览器兼容性,建议组合 dns-prefetch 以及 preconnet 使用:
<link rel="preconnect" href="https://s.alicdn.com/" crossorigin />
<link rel="dns-prefetch" href="https://s.alicdn.com/" />
预加载
对于页面依赖的核心资源,我们可以通过资源预加载的方式来提前下载关键资源,从而缩短 CRP 所需时间。效果如下:
通过在 html head 中添加 preload的 meta 标签实现:
- css:
- js:
后续需要加载对应的已经预载过的资源的时候就不需要从网络上重新获取了。
非核心内容异步
我们网站的内容非常丰富,这意味着功能复杂代码体量大。如果一定要在整个首屏加载完毕之后才能使用,那么用户体验就会很差。
为了解决这个问题,我们可以将非核心内容异步加载,这样用户可以在首屏加载完毕之后就可以使用网站的核心功能,而非核心内容则可以在后续加载完毕之后再使用。
方案上,对于使用 webpack 构建代码的用户,可以直接通过 dynamic import 来实现。
比如 PPC 的 PC 页面,我们把左侧的筛选进行了异步加载,以让用户能够更早的看到更为核心的商品 List :
import React, { lazy } from "react";
import SSRCompatibleSuspense from "../../component/ssr-suspense";
import { Icon } from "@alifd/next";
function LeftFilterAsync({ data }: { data: PPCSearchResult.PageData }) {
const TrafficLeftFilter = lazy(() =>
// NOTE:页面的左侧筛选,功能复杂,但不属于用户首屏需要的内容,所以异步加载
import(/* webpackChunkName: "left-filter" */ "@alife/traffic-left-filter")
);
const handleChange = (link: string) => {
xxx;
};
return (
<SSRCompatibleSuspense
fallback={
<Icon type="loading" />
}
>
<TrafficLeftFilter
data={data?.snData}
i18n={data?.i18nText}
handleChange={handleChange}
/>
</SSRCompatibleSuspense>
);
}
export default LeftFilterAsync;
选择性渲染
当代码不能进一步分割,但是渲染的内容有非常多,DOM 节点数量巨大,意味 CRP 的时间。那么在首屏可以选择性的渲染一部分更为关键的内容,这样可以减少首屏渲染的时间。
比如 showroom 的无线页面,首屏后端返回 48 个品的数量,而无线端的手机大部分首屏只能展示 4 个品,所以我们在首屏只渲染前 8 个品,后续的品则在 js ready 后进行二次渲染。
这样,对于同步直出的页面,即减少了 html 体积,可以加快下载 html 的速度,同时又减少了首屏 DOM 节点的数量,降低了浏览器生成 DOM Tree 的时间。
最终减少 CRP 所需要的时间。
FID 以及 CLS 的优化
前面大端的篇幅提到的都是 LCP 相关的优化,因为对于面向买家的页面来说,主要是纯展示型页面,一般没有非常复杂的交互,所以 FID 和 CLS 的问题不是很凸显,开发同学在意识上注意一下就好了。
FID
FID: First Input Delay , 从用户第一次与您的网站交互直到浏览器实际能够对交互作出响应的时间。
这个时间主要是由 js 的执行时间决定的,当浏览器的主线程执行 js 时,就无法相应用户的操作,最终影响 FID。那么优化的方向就是:
- 减少 js 的执行时长
- 分割 js 中繁重计算任务
减少 js 的执行时长
限制页面依赖的 js 总体积,可以非常直观的降低执行时长。
对于页面的主 js ,通过代码分割的方式延迟加载非首屏核心功能的代码,只有在代码真正要被使用,或者空闲的时候再去加载,将主线程空闲出来,从而减少 js 的执行时长。
对于页面依赖的二方包,一定要严格审查,避免同样的包、依赖比如 React、Fusion 等被重复引入,这样会导致 js 的体积增大,从而增加执行时长。比如我们某个场景中引入的一个二方 SDK,体积足足 1.6MB,比我们宿主页面代码的 300kb 还大,这里就有很大的优化空间。
控制第三方脚本的引入,或者尽可能延迟他们的加载,有些投放页面里面依赖了很多三方的统计脚本,这些脚本的加载会阻塞页面的渲染,从而影响 FID。
分割 js 中繁重计算任务
多余繁重的计算任务,可以通过 requestAnimationFrame 的方式,将计算任务分割到多个帧中执行,从而减少 js 的执行时长,给浏览器留出更多的空闲时间可以响应用户的操作。
如果是无法分割的计算任务,可以考虑使用 web worker 的方式,将计算任务放到 worker 中执行,从而不会阻塞主线程。
CLS
CLS: Cumulative Layout Shift , 通过计算未在用户输入 500 毫秒内发生的布局偏移的偏移分数总和来测量内容的不稳定性。
导致 CLS 较差的原因:
- 无尺寸的图像
- 无尺寸的广告、嵌入和 iframe
- 动态注入的内容
- 导致不可见文本闪烁 (FOIT)/无样式文本闪烁 (FOUT) 的网络字体
- 在更新 DOM 之前等待网络响应的操作
在国际站场景,核心需要注意的是:
- 图片需要设置具体的宽高而不是 auto ,这样浏览器在图片下载完成之前就知道该预留多少位置出来
- 页面主体部分尽量同步直出,对于异步渲染的区块,做好占位,不要因为异步渲染导致页面跳来跳去
基本上做到这些,那么 CLS 就可以达到标准。
策略沉淀
在我们这一年的优化过程中,沉淀了一些工具和经验来帮助我们快速的进行性能优化。
工具或系统沉淀
- agado*: *端架构团队打造的全球化性能度量平台,几行代码即可高效接入全面的性能度量系统;
- silkworm engine:买家基础技术在五年前左右开始搭建的一套通用同构渲染服务,满足除特定解决方案下(店铺、天马等)的页面快速接入同构能力的诉求,现在由 @咸鱼 维护;
- 流式渲染二方库:快速接入流式渲染的解决方案,并在前期打通了各层代理,后端接入成本可以从3人日减少到小时级别;
取得的成果
SEO 性能优化
Google Search Console 后台的 GoodUrl 比例增长:
- PC:0 -> 85.9%
- 无线:0-> 95.1%
具体性能指标(箭头指向优化后的结果):多个场景下页面的性能都有非常大的提升,CLS 和 FID 全部达到 cwv Good Url 标准,我们着重优化的两个场景中 LCP 也达到 Good Url 标准。 对于 SEO 场景,由于性能提升带来的搜索引擎加权,以及更好的到达率,在多个场景下都有** 10%~20% **的 uv 增长,大幅提升了用户规模。
付费页面优化
- Wap DPA 页面:LCP 降低了 500ms 左右,业务指标:uv 提升 9% 左右,其他业务指标如点击率、跨端等相关指标也有非常大的提升;
- PC PLA 页面:LCP 降低了 900ms 左右,业务指标:核心点击上升 16.1%,uv 增长 4.6%;
- 以及其他很多还在实验中的项目,都可以看到业务数据有不同程度的增长;
实际案例
前面说了非常多的理论知识,接下来结合一个实际的例子 —— 无线 showroom (一个 SEO 承接页)的优化,来验证我们如何根据上面的方法来将一个LCP、FID 以及 CLS 都不达标的页面优化为 Good Url 的。
现状分析
当我们接手 showroom 的时候,只知道性能很差,因为业务反馈说 Google Search Console 后台看到我们网站的 Good Url 的达标率为 0%,也就是说 LCP、CLS 以及 FID 都不及格。但具体差到什么样子,哪里差,一无所知。
优化的诉求非常迫切,但连现状是个什么样子都不知道,那自然是没有办法优化的。所以首先要有度量现状的方案,经过分析和调研,采用了 Google web-vitals 的库来获取用户数据,使用 ICBU 之前就对接 big-brother 来上报采集到的数据,同时通过配置 xflush 来实时展示数据的变动趋势。
这是最终的性能汇总大盘监控:
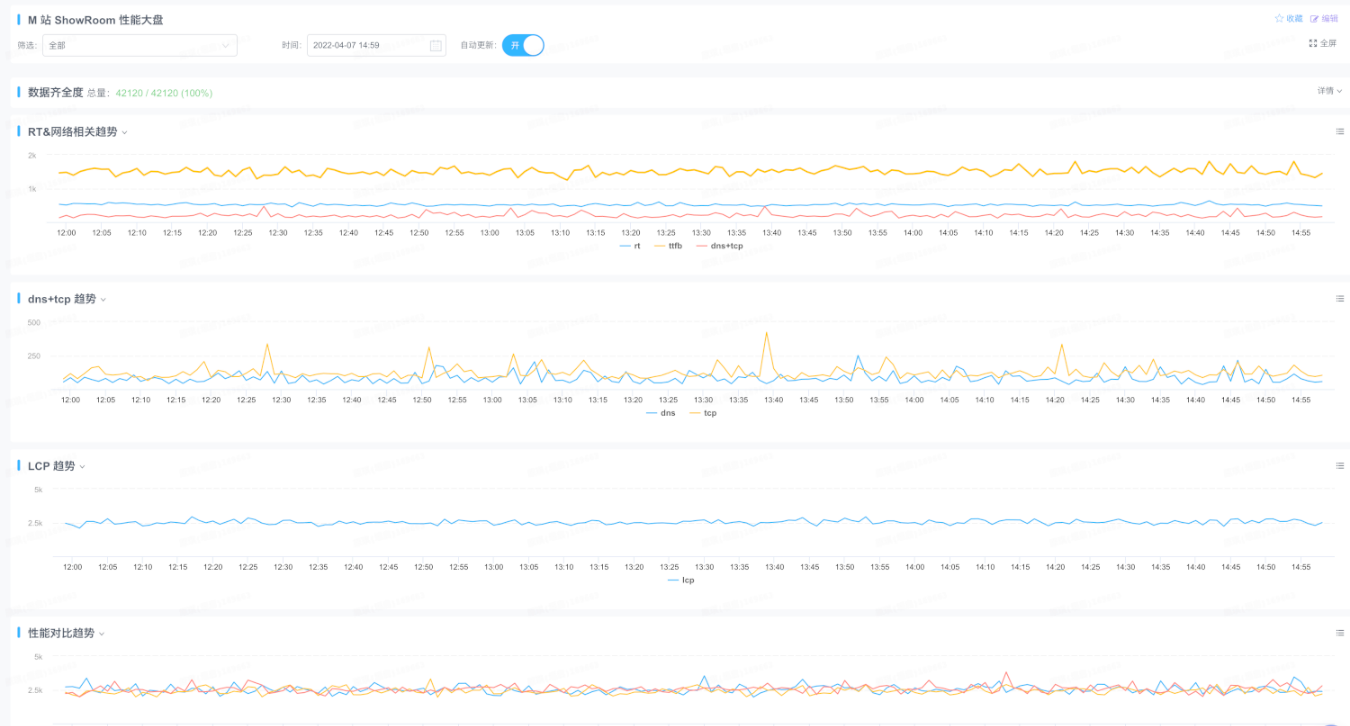
有了度量方案以后,我们得到了性能的现状:数据比较差,LCP、CLS 以及 FID 都需要进行优化。
有了性能数据以后,再来看一下 showroom 的技术架构:
- ui 框架采用的 rax + dx
- rax 是当时集团的类 react ui 库
- dx 是一个能够解决跨端开发问题的解决方案,主要用于端内 Android 和 iOS 的动态配置,Web 端也有兼容展示的方案
- 渲染链路:页面骨架上了 CDN,采用 js 调用异步接口获取首屏数据,然后异步完成页面的渲染
- 由于使用 dx, 需要从后端数据中获取 dx 模板的字符串,然后前端把字符串 evel 后作为通过 dx-h5 库转化为 rax 组件,再由 rax 渲染到页面上
- 样式文件:由于采用 rax 和 dx ,最终都是通过内联样式实现样式布局,没有独立的 css 文件供浏览器缓存
第一次同构改造
首先看 LCP 的组成:
 由于页面异步渲染的原因,即使 html 上了 CDN 也没有太大的帮助,整个渲染链路拉得非常长,我们接手后先做了同构改造。
由于页面异步渲染的原因,即使 html 上了 CDN 也没有太大的帮助,整个渲染链路拉得非常长,我们接手后先做了同构改造。
由于原本页面是 rax + dx ,rax 只是空壳,主要内容都是通过 dx 来渲染的, 所以需要对接 dx 的同构。刚好隔壁团队有一个 dx 的同构服务,我们尝试对了一下。
首先我们和 Akamai 的同学沟通,将 showroom 的 html 静态化方案从 CDN 上下了下来,然后前端层面做了一些改造对接了 DX 的同构。
对接完成后,虽然能够 dx 的同构也能实现直出,但是存在一个很严重的问题:服务端数据的 html 结构和前端渲染出来的结构不一样。
这导致前端 js 的二次渲染页面会闪动,毕竟 html 结构不一样,做不到像 react 那样的 hydrate ,LCP 的时间也变成了二次渲染完成后的时间,同时页面 FID、CLS 也没有太大的优化。
第二次同构改造
dx 的优势是一套配置,三端使用。但是在 Web 端实际的操作使用情况下,端内的配置用到 Web 端各种适配问题,最终发展成了一个组件,端内一套 dx 模板配置,端外另一套。也就是说端内外依然是各自独立维护模板,那么它的优势已经没有了。
同时由于使用了 dx,带了很多额外的问题:
-
渲染效率低下:“那么古尔丹,代价是什么?” dx 想要解决的是跨端配置的问题,但跨端就要有中间层,每加一层都是成本,导致最终的效率低下, LCP 和 FID 居高不下,之前维护的同学甚至还尝试过 wasm 的 dx 方案,但依然没有解决太多的问题。

-
dx 同构端的输出结构和浏览器端不一致,无法进一步的优化
在这些问题下, 我们最终选择了对 showroom 进行重构,将原本 dx、rax 的方案推到,用 react 进行了重写。
react 下各种技术方案都相对成熟,重构完成后对接了跑了很多年的 silkworm 的同构服务。react 的同构解决方案非常成熟了,不会出现 dx 下二次渲染页面需要闪动的问题,由于也没有胶水层,渲染效率相较于 dx 有了很大的提升。

可以看到渲染链路简单了非常多,从监控上看 LCP 降低了 900ms 左右,FID 直接降到了 Good 的标准 100ms 以下。
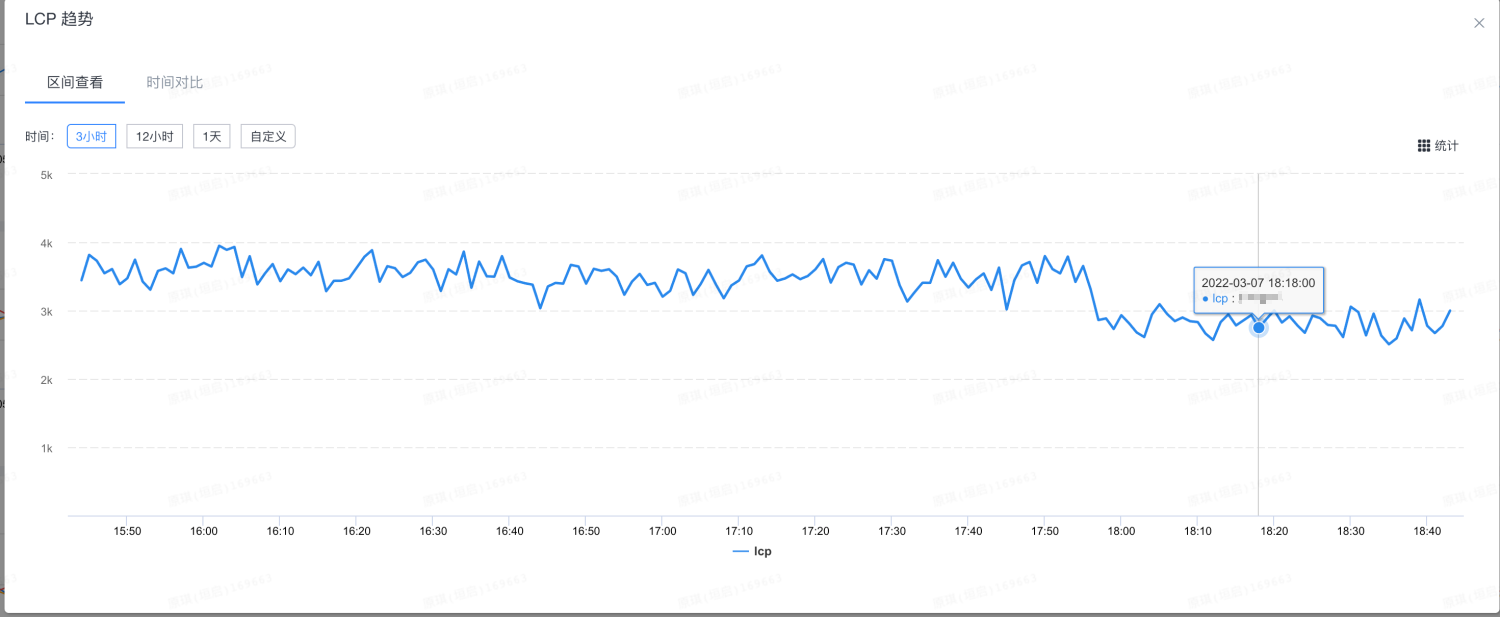
关键渲染路径优化
应用拆分
对原本的 showroom 应用进行了拆分,从一个大应用拆分为两个应用:基础公共包 traffic-base 以及上层业务应用 traffic-free-wap。
平时的发布基本都是 traffic-free-wap 的发布,traffic-base 的发布频率很低,提高缓存命中率,同时也降低了发布风险。
但是由于缓存的效果是一个长期的影响,短期内看不到 LCP 的变化。
aplus 异步改造
aplus 是集团打点方案,需要对接一个 aplus.js 的脚本来实现各种打点尤其是 pv 的上报。原本页面的 aplus.js 是同步加载和执行的,会阻塞页面的渲染,所以我们将其改造为异步加载。
需要修改的是后端服务中的 beacon 模块,在 beacon 模块中的给其中的 script 标签加上 async 就可以了:
[aplus]
aplusKeyUrl=.com
aplusKeyUrl=.net
aplusKeyUrl=.org
aplusKeyUrl=.cn
aplusKeyUrl=.hk
aplusKeyUrl=.vipserver
aplusLocation=header
aplusCmpType=find
aplusFilter=find"iframe_delete=true
aplusFilter=find"at_iframe=1
aplusFilter=find"/wangwang/update
aplusUrl=
<script
id="beacon-aplus"
async
src="//assets.alicdn.com/g/alilog/??aplus_plugin_icbufront/index.js,mlog/aplus_v2.js"
exparams="userid=\#getuid()\#&aplus&ali_beacon_id=\#getcookievalue(ali_beacon_id)\#&ali_apache_id=\#getcookievalue(ali_apache_id)\#&ali_apache_track=\#getcookievalue(ali_apache_track)\#&ali_apache_tracktmp=\#getcookievalue(ali_apache_tracktmp)\#&dmtrack_c={\#getHeaderValue(resin-trace)\#}&pageid=\#getpageid()\#&hn=\#gethostname()\#&asid=\#get_token()\#&treq=\#getHeaderValue(tsreq)\#&tres=\#getHeaderValue(tsres)\#">
</script>
aplus 异步改造上线后,从监控看获得了 50ms 的 LCP 提升。
预建联、预加载以及域名收拢
按照我们的优化策略,对 showroom 整个页面的静态资源域名都收敛到了 s.alicdn.com 下面。
同时对域名进行了 DNS 预解析和建联:
<link rel="preconnect" href="https://s.alicdn.com" crossorigin />
<link rel="dns-prefetch" href="https://s.alicdn.com" />
对于首屏的几个商品图,进行了预加载:
<link
rel="preload"
href="https://s.alicdn.com/@sc04/kf/H2df0c8cbb22d49a1b1a2ebdd29cedf05y.jpg_200x200.jpg"
as="image"
/>
<link
rel="preload"
href="https://s.alicdn.com/@sc04/kf/H423ae0f4cf494848bb5c874632270299J.jpg_200x200.jpg"
as="image"
/>
<link
rel="preload"
href="https://s.alicdn.com/@sc04/kf/Hdf15b5c8a7c544c2aee0b2616b2715e3K.jpg_200x200.jpg"
as="image"
/>
上线后, 从监控上看 LCP 有了 200ms 左右的提升,稳定在了 Good Url LCP 的边缘,即将达标。
流式渲染改造
做完以上优化后,我们开始进行流式渲染的改造,前后端一起打通了流式渲染的方案,预发测试效果非常好。但是上线后一直不生效,一直排查也排查不出来为什么。
最后想起来我们走了 Akamai 的动态加速,这意味着用户的请求还是先打到了 Akamai 的 CDN 上,然后再打到我们的后端服务上。而我们的流式渲染是在后端服务上进行的,所以有可能是 CDN 这里做了什么导致我们不生效。
和 CDN 的同学沟通后,发现需要加一个 chunked response streaming 的配置,加上后重新上线测试,流式渲染终于生效了,上线后 LCP 直接降低了 500ms,达到了 CWV Good Url 标准。
CLS 优化
LCP 和 CLS 达标以后,只剩下 CLS 还差一点。对于 showroom 来说,导致 cls 的问题主要是 header 的高度不固定,以及商品卡片中图标的位置不固定。
- 对于 header 的问题,我们和业务沟通后确定了 header 的高度,并加上了占位
- 对于 icon 图标的问题,针对性的设置固定宽度就可以了
优化总结
showroom 的优化过程就是根据我们前端提到的优化方法,度量->分析->实验,一步步推进,最终达到了 cwv Good Url 标准,search console 后台显示的 good rate 稳定在 90% 以上。
同时由于达到了 Google Good Url 的要求,获得了 Google 的搜索权重的加权。按照和 Google 对接的同学提供的衡量方法,wap showroom 的 Clicks +10.6%,Impression +8.8%,相当于额外带来 10% 左右的 uv。
总结
如果没有系统性的理论指导,性能优化很容易变成一件非常琐碎的事情,发现 A 解决 A ,发现 B 解决 B,随着业务迭代也会逐渐腐化,而且如果方向错误的话,很容易浪费大量的时间却拿不到想要的结果。
本文从性能优化的理论出发,从度量、分析、验证三个方面,介绍了我们在性能优化中的一些实践,希望能够帮助到大家。
虽然目前取得了一些性能和业务上的成果,但是很多页面比如付费承接依然有很大的优化空间,需要持续的优化和推进。
参考
本文章遵循: CC BY-NC-ND 4.0![]()
![]()
![]()
![]()
非商业转载请注明作者及出处,商业转载请联系 作者本人。
本文标题为:Alibaba.com 性能优化经验总结
本文链接为:https://blog.kisnows.com/2023/01/11/alibaba-buyer-performance-optimization-summary